In een eerdere blog is gekeken naar een 3D kaart met het aantal inwoners. Daarvoor is gebruik gemaakt van de vierkantstatistieken van het CBS. Daarin is Nederland verdeeld in vierkantjes met de statistieken die bij elk vierkantje hoort. Bijvoorbeeld het aantal inwoners, aantal koop- en huurwoningen, aantal mensen van een bepaalde leeftijd (0-14, 15-24, enz).
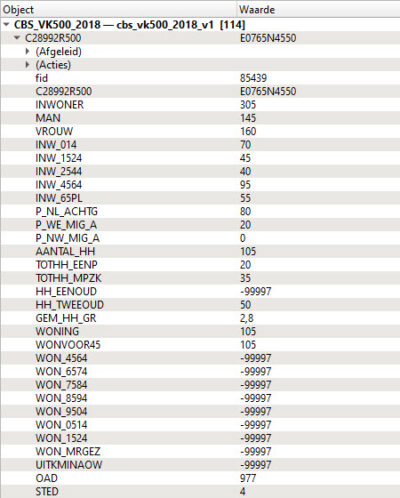
Daarmee kun je leuke dingen doen, zoals die 3D inwonerkaart liet zien. Maar hoe kun je nu de vakjes kleuren naar de leeftijdscatergorie die het grootst is? In het vakje hierboven zie je dat de leeftijdscategorie 45-64 het grootst is. Dat is een leuke puzzel!
Filteren en classificeren
Om te beginnen kun je alle vakjes wegfilteren waar geen bewoners zijn. Zoals je ziet in de data, wordt de waarde -9997 gebruikt om aan te geven dat er geen waarde is. Ik weet niet of dit consequent is toegepast, maar gewoon checken op ‘groter dan 0’ werkt ook. Zonder enige filter zie je heel Nederland.
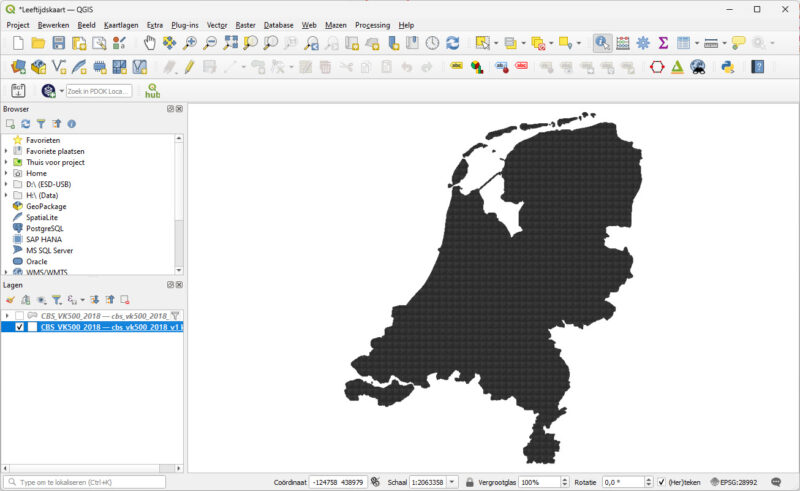
Je kunt bij Symbologie aangeven dat je de vakjes wilt verdelen in ‘INWONER > 0’ en de rest, dan krijg je dit:
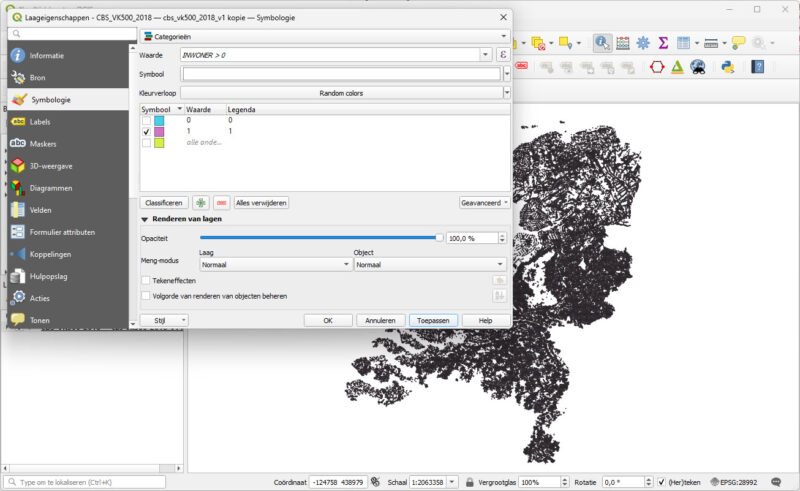
Maar je wilt eigenlijk in de Symbologie aangeven welke leeftijd het meest voorkomt. Het filteren op vakjes om mee te werken zul je op een andere manier moeten oplossen. Bijvoorbeeld bij het tabblad Bron, waar je een ‘Provider objectfilter’ kunt instellen via de Querybouwer:
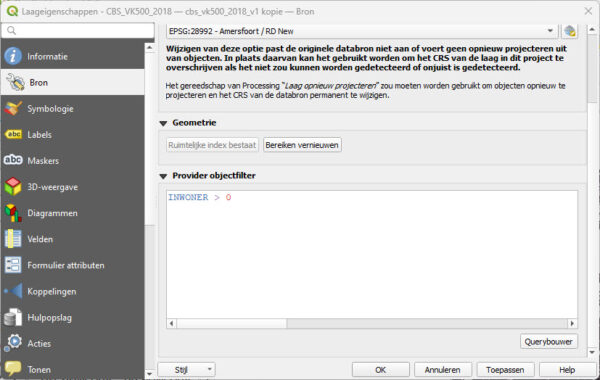
Dit levert hetzelfde op en nu heb je Symbologie nog beschikbaar voor het classificeren. Je kunt het wel combineren, maar dan moet je bij het classificeren in elke regel opnemen dat het aantal inwoners groter moet zijn dan 0.
Meest voorkomend
Je zou kunnen denken dat je de hoogste waarde moet opzoeken van de kolommen met leeftijdscategorieën. Maar je wilt niet de hoogste waarde, maar de kolomnaam met de hoogste waarde. Want wat heb je nu aan een getal als 95, als je vervolgens niet weet bij welke leeftijd dit hoort? Je wilt de kolomnaam ‘INW_4564’ terugkrijgen.
Dit zou met Python kunnen, maar met wat moeite ook met een expressie. Het ziet er wat complex uit maar dit zou een eerste poging kunnen zijn:
with_variable(
'col',
map("INW_014", 'INW_014', "INW_1524", 'INW_1524',
"INW_2544", 'INW_2544', "INW_4564", 'INW_4564',
"INW_65PL", 'INW_65PL'),
map_get(
@col,
array_first(
array_sort(
map_akeys(@col),
false
)
)
)
)
Je maakt hier een variable ‘col’ aan, en een dictionary (map) aan data, en daarop ga je zoeken naar de eerste waarde van een gesorteerde lijst van keys van die dictionary. Een dictionary is samengesteld uit keys en values, in dit geval telkens een combinatie van veldnaam en veldwaarde (“INW_014”, ‘INW_014′, enzovoort). Zoals je ziet is telkens de eerste waarde omgeven door dubbele aanhalingstekens en de tweede door enkele aanhalingstekens. De eerste retourneert de daadwerkelijke waarde van de kolom en de tweede is de naam. Gelukkig wil je hier maar op 5 kolommen zoeken, het valt dus mee om zo’n dictionary samen te stellen.
De volgende stap is het ophalen van de keys (de werkelijke waarden dus, in bovenstaand vakje 70, 45, 40, 95 en 55). Deze wordt omgekeerd gesorteerd zodat de hoogste waarde bovenaan staat. Vervolgens wordt daarvan de eerste waarde opgehaald, en met de functie map_get() wordt met deze waarde de bijbehorende value opgevraagd. Deze expressie geeft op bovenstaand vakje dus de tekst ‘INW_4564’ terug.
Wiskundig gezien zou je een dictionary eerder opzetten met een key-value-pair als veldnaam, veldwaarde in plaats van veldwaarde, veldnaam, zoals hier. Maar de functie map_get() kan alleen de value zoeken op basis van de key, en niet andersom.
De expressie geef je op in het tabblad Symbologie bij de weergave ‘Categorieën’. Het resultaat ziet er veelbelovend uit.
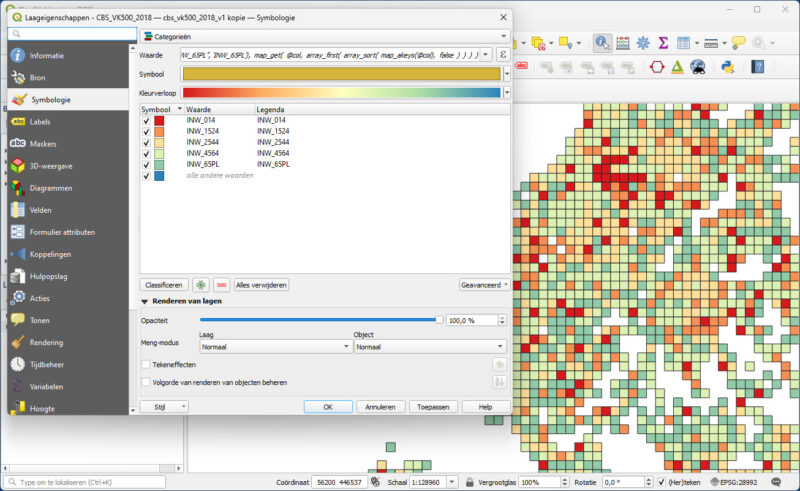
Check, check, dubbelcheck
Natuurlijk geloof je de uitkomst van de berekening niet voordat je het zelf gecheckt hebt. En helaas, de expressie blijkt niet te werken. In sommige gevallen krijg je niet de kolomnaam met de hoogste waarde terug. Maar waarom?
Na wat puzzelen lijkt het erop dat de functie map_akeys() de keys als string doorgeeft en niet als numerieke waarde. Wat op zich logisch is want in een dictionary is de key normaal gesproken een tekst, geen nummer. En dan wordt in de functie array_sort() niet gesorteerd op numerieke waarde, maar op tekstuele waarde. En dan blijkt dat de waarde 910 hoger is dan 2860, want 9 > 2.
Een nieuwe poging dan maar:
with_variable(
'col',
map(10000+"INW_014", 'INW_014', 10000+"INW_1524", 'INW_1524',
10000+"INW_2544", 'INW_2544', 10000+"INW_4564", 'INW_4564',
10000+"INW_65PL", 'INW_65PL'),
map_get(
@col,
array_first(
array_sort(
map_akeys(@col),
false
)
)
)
)
We tellen domweg overal 10.000 bij op (ervan uitgaande dat in elk groepje minder dan 10.000 personen zijn, wat je uiteraard ook eerst checkt). Nu krijg je in plaats van bijvoorbeeld: 910, 2860, 730, 330, 90 de waarden 10910, 12860, 10730, 10330, 10090. Sorteer je deze waarden, ook als string, dan krijg je de juiste waarde terug. Namelijk 12860. Met deze waarde als key kun je de waarde (en dus de veldnaam) halen uit de dictionary. Het gaat uiteindelijk toch niet om de daadwerkelijke waarde, maar om de kolomnaam. In vergelijking met het voorgaande plaatje zie je nu verschil in kleur.
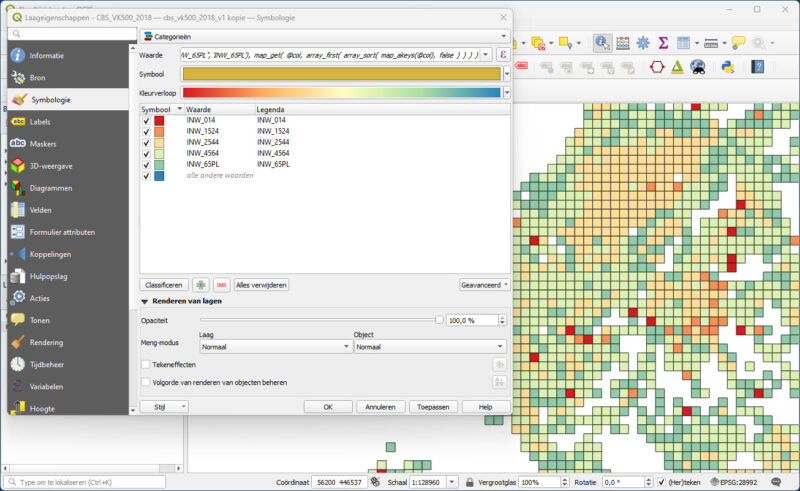
Je kunt nog overwegen om niet de veldnaam terug te geven, maar direct een mooie omschrijving. Dan stel je de dictionary samen met de veldwaarde plus 10.000 en een mooie omschrijving.
map(10000+"INW_014", '0 - 14 jaar', 10000+"INW_1524", '15 - 24 jaar',
10000+"INW_2544", '25 - 44 jaar', 10000+"INW_4564", '45 - 64 jaar',
10000+"INW_65PL", '65 plus')
Dit is alleen aan te bevelen als je verder niks meer met de veldnaam wilt doen. Je kunt in de ‘Categorieën’ in de Symbologie ook de legenda-tekst aanpassen, zodat de laagnaam alsnog keurig toont welke leeftijden er voorkomen in het vierkantje. En mocht je toch nog iets willen doen met de kolomnaam dan hoef je de expressie niet nog een keer aanpassen.
En ongetwijfeld kan het hele verhaal ook nog op andere manieren in QGIS.

Geen data-analist maar toch af en toe noodzaak om geodata te visualiseren? Dat kan met de applicatie QGIS. Dit boek helpt je op weg om de basisbeginselen onder de knie te krijgen en eenvoudig uit diverse bronnen zoals PDOK.nl, CBS en het Nationaal Georegister kaarten te genereren. This book is also available in English.

